Statistical Testing#
Theory of Statistical Testing#
In statistical hypothesis testing, what does a significant difference mean? Use an example for illustration, e.g., the difference in average weight of domestic and feral cats.
Given the same example as you used in task 1, what is your null hypothesis (\(H_0\)) and what is your alternate hypothesis (\(H_1\))?
When conducting a statistical test, one important outcome is a so called test statistic. What is a test statistic? Explain using the same example as you used in task 1.
When conducting a statistical test, one important outcome is a so called p-value. What is a p-value? Explain using the same example as you used in task 1.
Suppose we have compared the weight of domestic and feral cats using a statistical test. What does a p-value of
p=0.01tell us?What significance level (\(\alpha\)) of p-value would you use if you did a statistical test that may cause …
… someone to go to jail.
… a patient to take cough sirup.
Going back to our cat example:
If the calculated p-value does not pass your \(\alpha\) level, does that mean that the weight of domestic and feral cats is NOT different? Explain.
If the calculated p-value passes your \(\alpha\) level, what do you conclude?
What is a Type I and a Type II error?
Examples of Statistical Tests#
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import ranksums, ttest_ind
import warnings
# don't show deprecation warnings
warnings.simplefilter('ignore')
Comparing the difference of two (normal) distributions#
What is the null hypothesis of the Wilcoxon Rank-Sum test (also known as Mann-Whitney U test)?
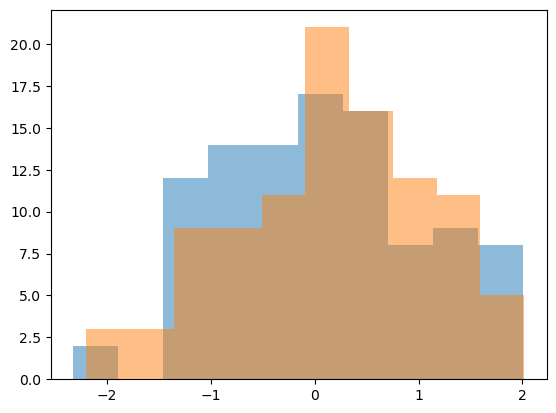
The following code generates data from two distributions and calculates the p-value based on the Wilcoxon Rank-Sum test. Try different
n_samples, andshift. Describe your observations.Could you also use the t-test for this data? Check the corresponding Wikipedia entry, Section ‘Uses’.
Rerun the following code multiple times with
shift = 0.2,variance = 1,seed = 0andn_samplesstarting from10, increasing it by10each time until you get a p-value below0.05. How could this procedure help you in obtaining significant results in basically every study that you do? Why is such a procedure (without mentioning its use) inacceptable in science? (Check this Wikipedia entry.)
# settings
n_samples = 100
shift = 0.2
variance = 1
rng = np.random.default_rng(seed=0)
# generate data
v1 = rng.normal(size=n_samples)
v2 = rng.normal(shift, variance, size=n_samples)
plt.hist(v1, alpha=0.5)
plt.hist(v2, alpha=0.5);
# perform the test
ranksums(v1, v2)
RanksumsResult(statistic=np.float64(-0.7696674994447229), pvalue=np.float64(0.4414971537739699))
Correlations#
Intuitively, what does the Pearson correlation coefficient measure? What is its minimum and maximum value and what do different values mean?
How to interpret a p-value calculated for Pearson correlation?
In what way is Spearman correlation different from Pearson?
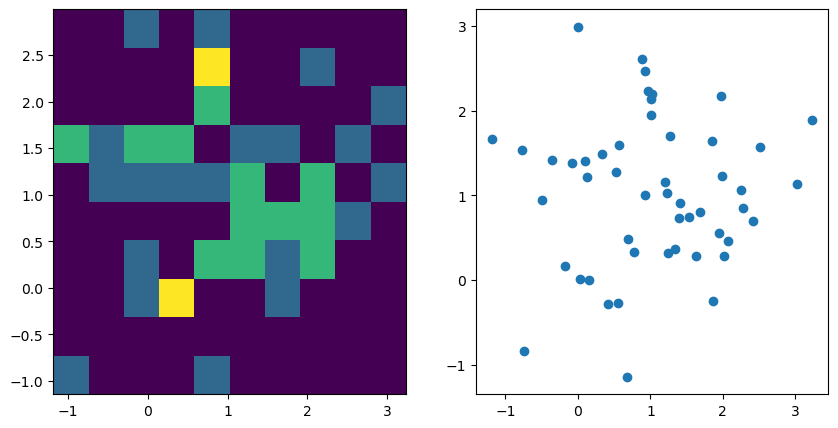
Look at the generated data below and run the code. Try different
n_samplesandcovariancevalues. What do you observe?Add the outlier of
(0, 99)to the data. What do you observe?The Spearman correlation (
scipy.stats.spearmanr) as well as Kendall’s tau (scipy.stats.kendalltau) are calculated in the next code cell. How does the outlier influence these correlation measures?
from scipy.stats import spearmanr, pearsonr, kendalltau
# try different sample sizes and covariances
n_samples = 50
# use values from -1 to 1
covariance = 0
# generate data
d = np.random.multivariate_normal((1,1), [[1,covariance],[covariance,1]], n_samples)
v1 = d[:,0]
v2 = d[:,1]
# plot
fig, axes = plt.subplots(1,2, figsize=(2 * 5, 1 * 5))
ax = axes[0]; ax.hist2d(v1, v2)
ax = axes[1]; ax.scatter(v1, v2)
# stats
r, p = pearsonr(v1, v2)
print(f"r={r}, p={p}")
r=0.04934816750554582, p=0.733611116780302
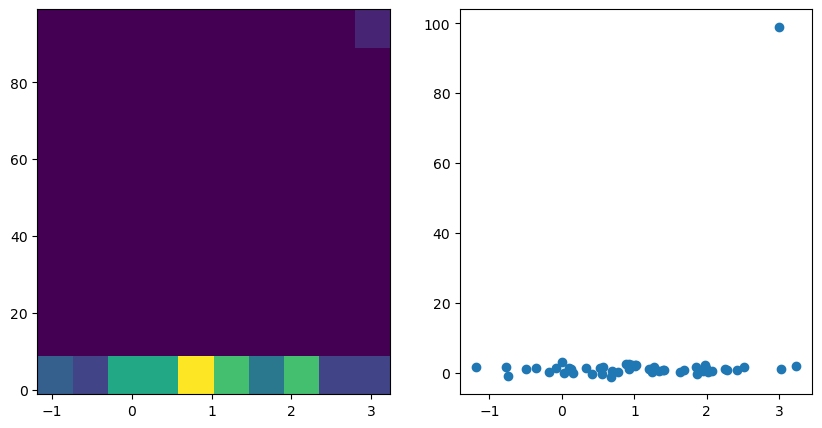
# add outlier
v1[0] = 3
v2[0] = 99
# plot
fig, axes = plt.subplots(1,2, figsize=(2 * 5, 1 * 5))
ax = axes[0]; ax.hist2d(v1, v2)
ax = axes[1]; ax.scatter(v1, v2)
# stats
r, p = pearsonr(v1, v2)
print(f"r={r}, p={p}")
print(spearmanr(v1, v2))
print(kendalltau(v1, v2))
r=0.27551968764546425, p=0.05279330564822759
SignificanceResult(statistic=np.float64(0.06276110444177671), pvalue=np.float64(0.6650215531503694))
SignificanceResult(statistic=np.float64(0.02857142857142857), pvalue=np.float64(0.7696979437812898))
Multiple Hypothesis Comparison#
Explain what the multiple hypothesis comparison is and why it is a problem (refer to p-values in the process).
Execute the following code, experiment with
n_samplesandp_threshold, and explain what it does.
# multiple hypothesis comparision and correction on real data
# try different p_thresholds (also called alpha values) and sample sizes
# parameters
n_samples = 1000
n_features = 1000
p_threshold = 0.05 # alpha value
# generate data
X = np.random.random((n_samples, n_features))
y = np.random.random(n_samples)
# calculate p-values between all features and the target
ps = []
for i in range(X.shape[1]):
r, p = spearmanr(X[:,i], y)
ps.append(p)
# report results
print(f"# of tests with p < {p_threshold} without correction: ", (np.array(ps) < p_threshold).sum())
from statsmodels.stats.multitest import multipletests
ps2 = multipletests(ps, method="fdr_bh")[1]
print(f"# of tests with p < {p_threshold} WITH correction: ", (np.array(ps2) < p_threshold).sum())
# of tests with p < 0.05 without correction: 42
# of tests with p < 0.05 WITH correction: 0
Model Comparison#
Run the given code. What does it do?
Adjust the given code to use repeated cross-validation (
StratifiedRepeatedKFold) for three different models (add one model). Why are we using astratifiedversion here?Run the training several times with different numbers of repetitions (1, 10, 100). What do you observe?
Compare your performance values using Wilcoxon rank-sum test. Again, compare different numbers of repetitions. What do you observe?
Is one of the two models significantly better? Why?
Retrain the “better” model on the whole training dataset and plot your predictions (
predict_proba) for the training and test data.
# imports
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split, cross_validate, StratifiedKFold, RepeatedStratifiedKFold
from sklearn.pipeline import make_pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import LinearSVC
import matplotlib.pyplot as plt
import seaborn as sns
# load data
data_titanic = pd.read_csv("exercise_01_titanic.csv", index_col="PassengerId")
def extract_features(data):
"""Extract features from existing variables"""
data_extract = data.copy()
# name
name_only = data_extract["Name"].str.replace(r"\(.*\)", "", regex=True)
first_name = name_only.str.split(", ", expand=True).iloc[:,1]
title = first_name.str.split(".", expand=True).iloc[:,0]
data_extract["Title"] = title
# ticket
# ...
return data_extract
data_extract = extract_features(data_titanic)
def preprocess(data):
"""Convert features into numeric variables readable by our models."""
data_preprocessed = data.copy()
# Sex
data_preprocessed = pd.get_dummies(data_preprocessed, columns=["Sex"], drop_first=True)
# Embarked
data_preprocessed = pd.get_dummies(data_preprocessed, columns=["Embarked"], dummy_na=True)
# Title
title = data_preprocessed["Title"]
title_counts = title.value_counts()
higher_titles = title_counts[title_counts < 50]
title_groups = ["higher" if t in higher_titles else t for t in title]
data_preprocessed["Title"] = title_groups
data_preprocessed = pd.get_dummies(data_preprocessed, columns=["Title"])
# drop the rest
data_preprocessed.drop(columns=["Name", "Cabin", "Ticket"], inplace=True)
return data_preprocessed
data_preprocessed = preprocess(data_extract)
# before inspecting the data, selecting and building models, etc.
# FIRST split data into train and test data (we set the test data size to 30%)
X = data_preprocessed.drop(columns="Survived")
y = data_preprocessed["Survived"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, stratify=y)
def evaluate(model, name, scoring="accuracy"):
results = cross_validate(
model,
X_train, y_train,
cv=StratifiedKFold(n_splits=5),
scoring=scoring,
return_train_score=True)
results = pd.DataFrame(results)
results["model"] = name
print(f"Train ({scoring}): {results['train_score'].mean():.02f} +/- {results['train_score'].std():.02f}")
print(f"Test ({scoring}): {results['test_score'].mean():.02f} +/- {results['test_score'].std():.02f}")
return results
results = []
imputer = SimpleImputer(strategy="median")
scaler = StandardScaler()
model_lr = LogisticRegression()
pipeline_lr = make_pipeline(imputer, scaler, model_lr)
results_lr = evaluate(pipeline_lr, "logistic regression")
results.append(results_lr)
Train (accuracy): 0.83 +/- 0.01
Test (accuracy): 0.82 +/- 0.03
imputer = SimpleImputer(strategy="median")
model_tree = DecisionTreeClassifier(max_depth=3)
pipeline_tree = make_pipeline(imputer, model_tree)
results_dt = evaluate(pipeline_tree, "decision tree")
results.append(results_dt)
Train (accuracy): 0.83 +/- 0.01
Test (accuracy): 0.81 +/- 0.03
results_df = pd.concat(results)
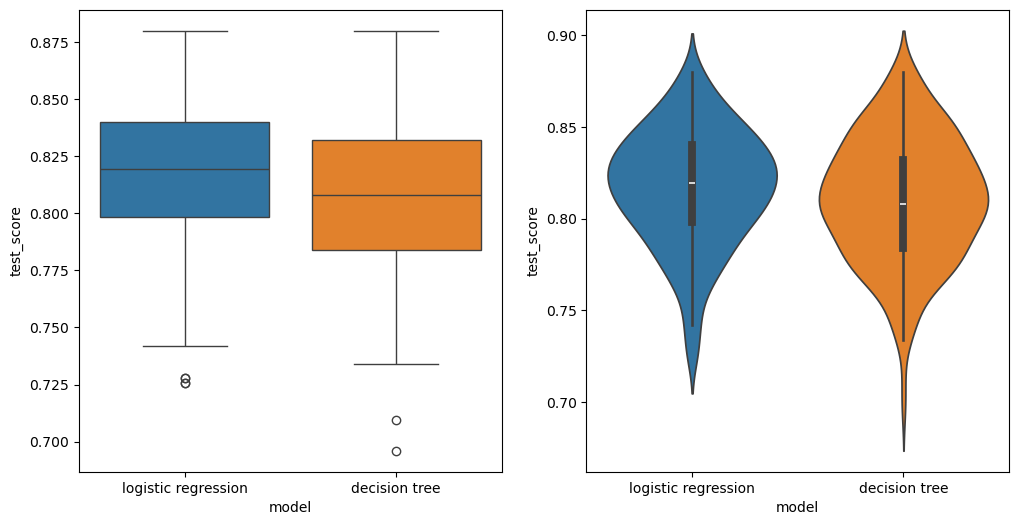
fig, axes = plt.subplots(1, 2, figsize=(2 * 6, 6))
ax = axes[0]
sns.boxplot(data=results_df, x="model", y="test_score", ax=ax, hue=results_df["model"])
ax = axes[1]
sns.violinplot(data=results_df, x="model", y="test_score", ax=ax, hue=results_df["model"])
<Axes: xlabel='model', ylabel='test_score'>
# compare
from scipy.stats import ranksums
test_score_lr = results_df.loc[results_df["model"] == "logistic regression", "test_score"]
test_score_dt = results_df.loc[results_df["model"] == "decision tree", "test_score"]
# ...